Beeld- en geluidsherkenning
26 oktober 2023 · Vincent Kalkman & Laurens Hogeweg · 5484 × bekeken

Beeld- en geluidsherkenning
Het zal veel mensen bekend voorkomen. Je kijkt op Waarneming.nl of er nog iets gezien is en tussen enkele leuke soorten staat een onwaarschijnlijke waarneming. Op de een of andere manier voel je vaak al aan dat er iets mis is. Bij het openen van de waarneming zal het tegenwoordig vaak blijken te gaan om een waarneming op basis van beeldherkenning. Om zout in de wonden te strooien staat er vaak nog iets bij als ‘zelf dacht ik dat het een buizerd was, maar ObsIdentify zegt 69% zeker een Steenarend’. Beeldherkenning levert naast dit soort ergernissen, die vaak meer te maken hebben met de luiheid van de waarnemers dan met beeldherkenning, ook heel veel voordelen op.
Beeldherkenning
Beeldherkenning is de afgelopen jaren voor veel natuurliefhebbers een vast onderdeel van hun leven geworden. Veel gebruikers weten weinig over hoe het tot stand komt en dat Nederland een van de voorlopers is op het gebied van beeldherkenning voor biodiversiteit. Dat laatste komt door de zeer goede samenwerking tussen Naturalis Biodiversity Center en Stichting Observation International, de club achter Waarneming.nl, Waarnemingen.be en Observation.org. Bijna iedereen maakt gebruik van deze drie websites maar zelden denken mensen na over hoe bijzonder ze zijn. Meer dan 100.000 gebruikers verzamelen jaarlijks meer dan 50 miljoen waarnemingen, resulterend in bijna 80 miljoen foto’s die door honderden zeer kundige validatoren gecontroleerd zijn. De websites staan dag en nacht voor je klaar, zijn zelden uit de lucht en verzamelen meer Europese biodiversiteitsdata dan enig ander biodiversiteitsportal. Naturalis is begin 2018 serieus begonnen met het ontwikkelen van beeldherkenning voor biodiversiteit, iets wat zonder de samenwerking met Waarneming.nl onmogelijk was geweest. Het lastigste van het ontwikkelen van beeldherkenning lijkt misschien het bouwen van de AI-modellen maar minstens net zo lastig is het vinden van trainingsdata. Om een soort goed te herkennen zijn het liefst vele honderden beelden nodig en de beeldenbank van Waarneming.nl is daarbij cruciaal. Na het initiële succes van de eerste beeldherkenningsmodellen heeft Naturalis sterk geïnvesteerd in het verder ontwikkelen en de volgende ambitie uitgesproken:
“Beeld- en geluidsherkenningsdiensten beschikbaar maken voor alle Europese soorten die jaarlijks door honderdduizenden waarnemers worden gebruikt en resulteert in vele miljoenen betrouwbare observaties.”
Het ‘alle Europese soorten’ moet natuurlijk met een korreltje zout worden genomen. Maar binnen enkele jaren zullen we wel op een model met meer dan 50.000 soorten zitten terwijl het aantal gebruikers en waarnemers nu al richting de respectievelijk 100-duizenden en miljoenen gaat.
De beeldherkenningsmodellen worden jaarlijks opnieuw getraind binnen het Naturalis AI team welke zich richt op het trainen en evalueren en beschikbaar maken van modellen op grote schaal. Regelmatige updates zijn nodig deels omdat de techniek steeds beter wordt maar ook omdat er van steeds meer soorten trainingsdata beschikbaar komt. Voor het doorontwikkelen van de techniek is postdoc Rita Pucci in dienst bij Naturalis. Zij test verschillende type technieken om modellen te maken waarbij ze niet alleen kijkt naar welk model de meeste voorspellingen goed heeft, maar ook naar welke modellen goed werken voor soorten met weinig trainingsdata. Om de hoeveelheid trainingsdata te vergroten maar ook om kosten te kunnen delen is in 2023 voor het eerst een model gemaakt met data van biodiversity portals uit Groot-Brittannië, Noorwegen, Zweden, Finland, en Denemarken. In totaal zijn 35 miljoen beelden gebruikt die betrekking hebben op ca. 38000 taxonomische namen, waaronder ruim 31000 soorten. Het afstemmen van de naamgeving tussen partners is daarmee een substantieel deel van het werk. Doordat het beeldherkenningsmodel nu ook door deze portals wordt gebruikt is het met recht de meest gebruikte Europese ‘veldgids’ geworden. In veel landen zien we hetzelfde als wat er bij de introductie van beeldherkenning in Nederland zichtbaar was, een sterke toename van het aantal waarnemingen vooral bij groepen waar geen veldgidsen van voorhanden zijn. Zo neemt het aantal Europese waarnemingen van veel soorten wantsen nu met tientallen procenten per jaar toe, simpelweg omdat je ze nu makkelijk op naam kan brengen.
 Morinelplevier Charadrius morinellus, Oude Land van Strijen (ZH), 3 oktober 2023, Merijn Loeve. Morinel zit vaak op grote afstand maar blijft fotogeniek. Beeldherkenning weet daardoor niet goed waar het naar moet kijken en leert daardoor een landschap te herkennen als een soort.
Morinelplevier Charadrius morinellus, Oude Land van Strijen (ZH), 3 oktober 2023, Merijn Loeve. Morinel zit vaak op grote afstand maar blijft fotogeniek. Beeldherkenning weet daardoor niet goed waar het naar moet kijken en leert daardoor een landschap te herkennen als een soort.Beeldherkenning is niet perfect. Iedereen zal wel eens een foto van een persoon door de beeldherkenning hebben gehaald om te kijken of hij of zij een Eikhaas of een Slijmerige blekerik is. Dat laat gelijk een van de beperkingen zien van beeldherkenning, je krijgt altijd een antwoord, ook al zit de soort in kwestie helemaal niet in het model. Vervelender is dat beeldherkenning soms een fout antwoord geeft maar daar wel heel zeker over is. In combinatie met dommig gebruik kan dat leiden tot irritante waarnemingen op Waarneming.nl. Soms zijn de vergissingen van beeldherkenning onbegrijpelijk maar vaak zit er wel een logica achter. Een klassiek voorbeeld is dat kale akkers regelmatig herkend worden als Morinelplevier. Dit komt simpelweg omdat veel foto’s van morinelplevieren bestaan uit akkers met daarin een net herkenbare Morinel. Bij alle soorten spelen dit soort achtergrond effecten een rol. Zo zal bij sommige bijen de bloem waarop ze zitten ook een rol spelen bij de herkenning (bijvoorbeeld Knautiabij). Overigens is dat niet veel anders dan hoe wij mensen een soort op naam brengen. Tijd, locatie en achtergrond bepalen onze eerste voorspelling – maar als het goed is hebben we daarna de discipline om ook echt naar de expliciete kenmerken te kijken. Iets wat de beeldherkenning voorlopig nog niet zal doen op de benodigde schaal van tienduizenden soorten. Wel wordt binnen het Naturalis AI team, onder leiding van de tweede auteur [LH], hard gewerkt om “onherkenbare” waarnemingen (selfies, landschappen, slechte foto’s, maar ook soorten niet in de database) betrouwbaar te kunnen markeren via andere AI technieken.


Het voorkomen van domme waarnemingen van zeldzame soorten kan deels via de apps/websites of via AI techniek worden opgelost (wordt aan gewerkt) maar zit ook in het begeleiden van nieuwe waarnemers. Veel validatoren besteden veel tijd aan het aan nieuwe waarnemers uitleggen hoe je wel een goede waarneming doorgeeft. Dit is heel belangrijk maar soms ook vermoeiend werk. De eerste auteur van dit stuk heeft een keer een waarnemer die een slechte foto van een huismus had doorgegeven als Zuringrandwants gesuggereerd dat die beter een andere hobby kon zoeken. Als reactie kreeg hij een bericht van de moeder van de waarnemer, waarin ze vertelde dat haar negenjarige dochter het niet met opzet had gedaan en echt haar best had gedaan. De eerste auteur [VK] voelt zich daar tot de dag van vandaag schuldig over.
Voor vogels zijn er natuurlijk goede en toegankelijke veldgidsen en wat dat betreft profiteren ze minder van beeldherkenning dan andere groepen. Wel zie je dat veel hobbyfotografen die minder geïnteresseerd zijn in zelf herkennen gebruik maken van beeldherkenning en ongetwijfeld zal regelmatig een vogelaar door de beeldherkenning gecorrigeerd worden bij het uploaden van een foto van een vermeende Matkop of Wespendief. Beeldherkenning heeft ondertussen ook al enkele mooie ontdekkingen gedaan (bijvoorbeeld de Huismus van Garderen). Ongetwijfeld zal voor veel toekomstige vogelaars de beeldherkenning dezelfde rol in hun leven vervullen als de Tirion, Peterson of Johnssons voor de huidige generatie (oudere) vogelaars.
Geluidsherkenning
Naast beeldherkenning wordt er ook hard gewerkt aan geluidsherkenning. Daarbij worden modellen niet getraind met foto’s maar met sonogrammen. Sonogrammen zijn eigenlijk gewoon plaatjes en veel van de gebruikte techniek is daarom hetzelfde. Wel levert geluid weer andere problemen op. Het is zelden dat op een opname alleen de doelsoort te horen is en meestal hoor je verschillende soorten door elkaar heen met daarbij nog achtergrondgeluiden zoals pratende mensen, auto's, vliegtuigen of de wind die op de microfoon blaast. Veel mensen zullen vertrouwd zijn met de geluidsherkenning van birdNET waarin de 3.000 wereldwijd algemeenste soorten zijn opgenomen. Naturalis richt zich in eerste instantie op het maken van geluidsherkenning voor Europese vogels, vleermuizen, sprinkhanen en zeezoogdieren hoewel we uiteindelijk ook de amfibieën, vissen en cicaden willen doen. Het primaire doel is om de analyse van lange opnames (uren, dagen of zelfs opnames van weken) mogelijk te maken zodat geluidsherkenning gebruikt kan worden voor monitoring. Je kan daarbij denken aan geluidsapparatuur die in een broedvogelkolonie staat en verstoring meet of aan mensen die met geluidsapparatuur op de fiets monitoring uitvoeren van landbouwgebieden. Natuurlijk willen we de verschillende modellen met elkaar combineren zodat het mogelijk wordt om met een opname zowel vogels, vleermuizen en sprinkhanen te monitoren. In Nederland heeft dit voordelen maar de winst zit hem natuurlijk vooral in gebieden waar er minder vrijwilligers zijn.
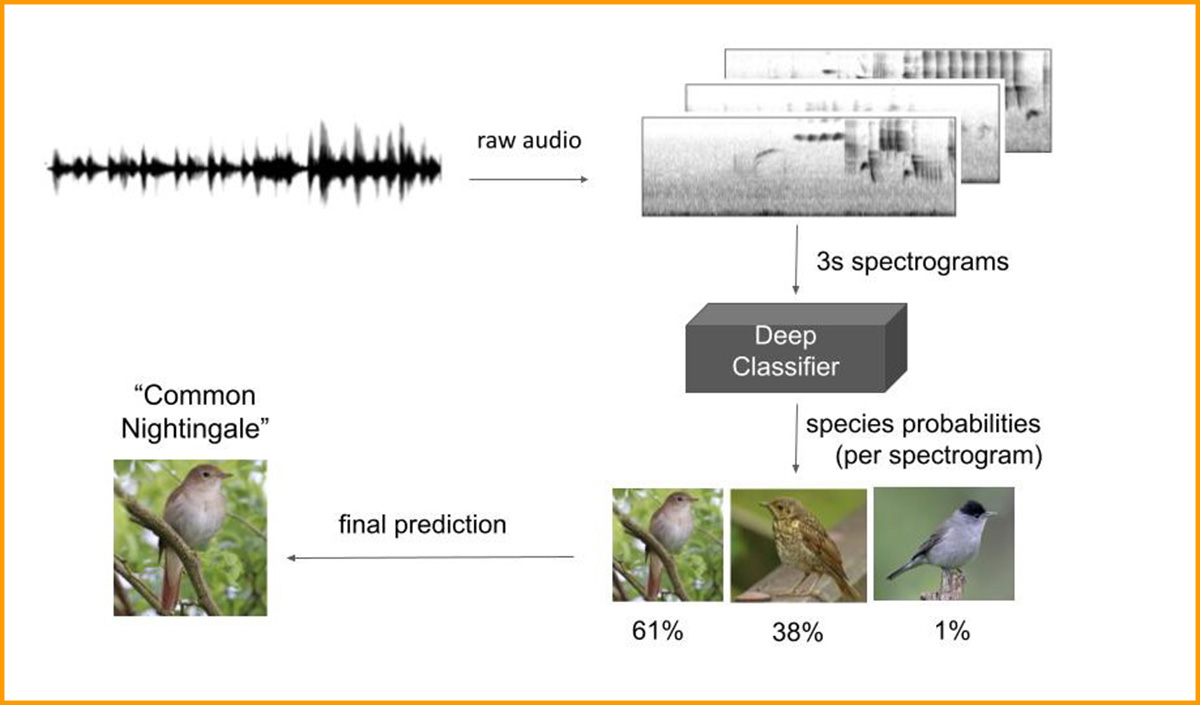 Simpel overzicht van hoe geluidsherkenning werkt. De opname (wav-file) wordt opgedeeld in spectrogrammen van elk drie seconden lang. Na analyse wordt de soort met de hoogste waarschijnlijkheid geselecteerd, daarbij wordt rekening gehouden met de voorspellingen van de drie seconden voor en drie seconden na het bewuste stukje (lopend gemiddelde). Afhankelijk van het doel kan er vervolgens nog gefilterd worden op locatie.
Simpel overzicht van hoe geluidsherkenning werkt. De opname (wav-file) wordt opgedeeld in spectrogrammen van elk drie seconden lang. Na analyse wordt de soort met de hoogste waarschijnlijkheid geselecteerd, daarbij wordt rekening gehouden met de voorspellingen van de drie seconden voor en drie seconden na het bewuste stukje (lopend gemiddelde). Afhankelijk van het doel kan er vervolgens nog gefilterd worden op locatie.Burooj Ghani, de postdoc die aan dit project werkt bij Naturalis heeft een eerste model voor Europese vogels gereed en dit model lijkt net zo goed of zelfs iets beter te werken dan het model van birdNET. Komend voorjaar gaan studenten van de Universiteit Leiden testen of monitoring op basis van geluid mogelijk is. Mogelijk werkt het model ook goed voor de analyse van lange nachtopnames van trekvogels. Heb je van dit soort opnamen en wil je die voor een test beschikbaar stellen neem dan contact op met de eerste auteur.
Net als bij beeldherkenning zijn voor het succes drie factoren van belang, trainingsdata, de techniek om modellen te maken en het vertalen van de resultaten naar de gebruiker. Trainingsdata is bij geluid een grote uitdaging. Hiervoor wordt nauw samengewerkt met Xeno-canto, wereldwijd de grootste vrij toegankelijke website voor natuurgeluiden. Het geluidsherkenninsgmodel voor Europese vogels is geheel op hun data gebaseerd. Ondanks het enorme aantal op Xeno-canto beschikbare opnamen zijn er nog steeds vogels waarvan te weinig opnamen beschikbaar zijn. Geluidsopnamen uit andere bronnen, zoals Waarneming.nl, worden niet gebruikt omdat de opnamekwaliteit vaak matig is (in grotere mate dan bij beelden het geval is). Bij sprinkhanen en vleermuizen is het nog lastiger om goede en betrouwbaar op naam gebrachte opnamen te krijgen. Momenteel wordt er voor de 1200+ Europese sprinkhanen een inhaalslag gemaakt en binnenkort zal een groot aantal daarvan te beluisteren zijn op Xeno-canto. Net als bij beelden zijn er bij geluid lastige maar ook grappige problemen met de trainingsdata. Een mooi voorbeeld daarvan betrof een opname die onlangs zonder verdere informatie uit Griekenland werd gestuurd. De analyse liet zien dat er in het eerste uur van de opname regelmatig een Waterspreeuw aanwezig was, maar daarna werd er doorlopend en met grote zekerheid Scopeli’s Pijlstormvogel voorspeld, een nogal ongebruikelijke combinatie van vogelsoorten. Bij naluisteren bleek het eerste uur geen Waterspreeuw te bevatten maar wel het breken van de golven op de rotsen. Op opnames van Waterspreeuw is bijna altijd ook het geluid van een beek te horen en op basis daarvan had het model geleerd dat het geluid van water wat tegen stenen aanslaat betrekking heeft op Waterspreeuw.
Aan de laatste stap, het vertalen van de analyse naar de gebruiker toe, moet nog gesleuteld worden. Bij het herkenningsmodel voor vogels wordt van elke drie seconden een voorspelling gedaan. Een opname van 24 uur leidt daardoor in potentie tot bijna 29.000 voorspellingen waardoor de kans op een flink aantal incorrecte voorspellingen ook toeneemt. Gebruikers moeten dus in staat worden gesteld om fouten er snel uit te filteren. In het bovengenoemde voorbeeld van de Waterspreeuw kon dat heel makkelijk op basis van de zekerheid van identificatie maar vaak zal ook de frequentie waarmee een soort gehoord wordt een rol kunnen spelen. Zo is het onwaarschijnlijk dat in een opname van 24 uur een grote karekiet maar 12 seconden zingt. Door het snel kunnen opzoeken en na luisteren van dit soort uitbijters kunnen gebruikers hun eigen data schonen.
Is dit wel leuk?
Het zal de oudere lezers zijn opgevallen dat jonge vogelaars tegenwoordig veel meer kunnen en weten dan zijzelf op die leeftijd. Mogelijk komt dit doordat vogelen tegenwoordig meer capabele mensen aantrekt maar waarschijnlijker komt dit simpelweg door betere veldgidsen, het voorhanden zijn van eindeloos veel foto’s op internet, betere verrekijkers, betere camera’s en betere communicatie. Beeld- en geluidsherkenning is daarin weer een volgende stap. Het gevaar is dat waarnemers hierdoor lui worden en deels gebeurt dat zeker. Maar over het algemeen zie je ook dat mensen die echt geïnteresseerd zijn uiteindelijk ook zelf willen weten hoe ze een soort kunnen herkennen. De positieve effecten van beeld- en geluidsherkenning zijn overduidelijk. Meer mensen kijken naar planten en dieren en geven hun waarnemingen door en bijna alle vogelaars maken uitstapjes naar andere diergroepen. Dit effect zal in andere landen met een minder goed ontwikkeld netwerk van vrijwilligers en waar veldgidsen vaak niet voorhanden zijn nog groter zijn. En stiekem droomt iedereen ervan, jij die lekker warm binnen aan de koffie zit terwijl buiten in de gure wind je telescoop op het terras staat en de langsvliegende zeevogels op naam brengt.
Vincent Kalkman, onderzoeker Image & sound recognition for citizen science, Naturalis Biodiversity Center
Laurens Hogeweg, Naturalis AI team, Naturalis Biodiversity Center
Discussie

Vincent van der Spek
·
26 oktober 2023 16:13, gewijzigd 26 oktober 2023 16:21
Ha ha, als dat al een droom is, dan toch zeker een nachtmerrie. Stel je voor dat je zelf niet eens meer hoeft te kijken!
Maar fijne, heldere uiteenzetting! Ik ben ook zeer content met de mededeling dat er gewerkt wordt aan het voorkomen van 'domme' waarnemingen van zeldzame soorten. Dit is een spannende ontwikkeling, maar wat mij betreft is het wel te vroeg in de ontwikkelfase openbaar ingezet. Velen van ons zijn semi-afgehaakt ('ik blijf aan de gang'), en de klachten hierover leken niet zo serieus genomen...
Dat gezegd hebbende gebruik ik het zelf ook met plezier voor onbekende soortgroepen.
Tot slot nog een vraag: ik vermoed dat er een bias richting zeldzaamheden ontstaat omdat die relatief (en misschien zelfs wel absoluut!) meer gefotografeerd worden en op wrn.nl gezet, en dat daarmee de AI beter gevoed wordt met bijv. Iberische dan met 'gewone' tjiffen (om een hinderlijke 'standaardfout' te noemen). Klopt dat?

Vincent Kalkman
·
26 oktober 2023 19:56
Ja, er wordt inderdaad gecorrigeerd voor het aantal foto’s wat van een soort beschikbaar is. Overigens worden er sowieso per soort maar maximaal 5000 foto’s voor training gebruikt. Naast foto’s van Waarneming.nl worden ook foto’s van Observation.org gebruikt. Hierdoor zullen de meeste vogelsoorten ruimschoots in de fotoselectie vertegenwoordigt zijn.

Wim Wiegant
·
26 oktober 2023 22:49, gewijzigd 26 oktober 2023 23:08
Ik vond het leuk en zeer leerzaam om te lezen...!
AI kende ik vooral uit de wereld van spellen als schaak en go, en bij schaak is het onverslaanbaar, maar bij go bleek er zelfs na het verslaan van de wereldkampioen een paar jaar geleden, een enorm gat te bestaan: het programma was, met een eenvoudige strategie met veel suboptimale zetten, makkelijk te verslaan...! De AI was niet getraind op deze strategie, en maakte daarom vrij domme fouten! Ik neem aan dat dat tegenwoordig niet meer zo is, maar dat heb ik niet uitgezocht.
Maar bij het herkennen van vogels, om maar eens de getoonde Morinelplevier als voorbeeld te nemen: ik zou denken dat met enige inspanning het onderwerp van de foto te isoleren zou kunnen zijn. Daarmee zou het probleem van het herkennen van kale akkers als Morinelplevieren toch te voorkomen moeten zijn...?
Dat de ontwikkeling van AI (training, en daarna herkenning) en het menselijk brein bij benadering hetzelfde werken, mag het volgende voorbeeld verduidelijken. Ik ben in supermarkten, in de tijd dat ik nog altijd een stropdas aan en een pet op had, meer dan eens door heel kleine kleuters aangeroepen met: "Opa...!", hetgeen dan niet juist bleek te zijn. De non-artificial intelligence van kleine - nog trainende - kinderen werkt wel net als AI: pet, kaal, stropdas, dat moet wel opa zijn...!
Vincent Kalkman
·
26 oktober 2023 23:30
Een van de dingen die ik heb geleerd van het samenwerken met AI-mensen is dat je niet slim moet proberen te zijn en de AI zoveel mogelijk de problemen zelf moet laten oplossen. Je kan inderdaad de foto’s van morinel bijsnijden maar we hebben het in totaal over 35.000.000 foto’s - die kan je nooit allemaal langslopen. Het probleem kan daarom het beste aan de invoer kant worden opgelost: mensen moeten beeldherkenning alleen gebruiken bij foto’s waar het te identificeren object duidelijk is. De belangrijkste tip die je deze week zal lezen is dan ook dat je goed gebruik moet maken van de optie om foto’s bij te snijden. In ObsIdentify is deze optie ingebouwd en het wel of niet bijsnijden heeft sterke invloed op de resultaten. Overigens heeft het AI-team gewerkt aan auto-zoom waarbij op basis van de attentiemap aan de gebruiker een voorstel wordt gedaan voor het bijsnijden van de foto. Dit is een van de dingen die komende jaren hopelijk beschikbaar komen.

Klaas Zwaan
·
29 oktober 2023 20:27, gewijzigd 29 oktober 2023 20:28
Dank voor dit boeiende artikel. Ik maak steeds meer gebruik van de genoemde technieken, vooral de herkenning op basis van geluid. Voor een vogelaar met wat gehoorschade is dat ideaal. ;-)
Ik kijk erg uit naar de ontwikkelingen op korte termijn!

Jan Hein van Steenis
·
30 oktober 2023 12:07
Bij planten is het probleem vaak dat waarnemers alleen de bloem fotograferen, wat dan een antwoord oplevert dat niet te controleren is. De meeste mensen komen niet verder dan bloemperkjes en tuinen, wat dan weer tot rare antwoorden van de AI leidt (bijna elke exotische waarneming die ik in Duitsland tegenkom is een tuinplant die er totaal niet op lijkt).
Voor groepen waar ik geen verstand van heb is de beeldherkenning een heel handig hulpmiddel. Plantnet wist me bij sommige soorten in Peru aardig op weg te helpen.
(Dat ook nog eens de GPS-data door Samsung compleet absurd worden overgenomen is controle echt een crime... maar dat heeft niets met beeldherkenning te maken).

Wietze Janse
·
31 oktober 2023 08:49, gewijzigd 31 oktober 2023 20:26
Vincent,
Bedankt voor je uitgebreid verhaal en het wat meer inzicht geven in de achtergronden. Ik weet dat de nauwkeurigheid per soortgroep wisselt, ik kan niet over andere soortgroepen praten, wel over vogels. Ik test om de zoveel tijd een paar van deze applicaties uit en vergelijk dan een beetje de nauwkeurigheid. Ga nu even niet hier dieper op in, behalve dat Google Lens de laatste tijd aanzienlijk verbeterd is.
Maar de uitkomsten zijn gebaseerd (corrigeer me als ik fout zit) op het vergelijken van plaatjes en derhalve afhankelijk van de kwaliteit van de plaatjes. Juiste uitsneden zijn belangrijk om het meenemen van omgeving (zie je voorbeeld Morinelplevier) te voorkomen. Dan vraag ik me af hoe ga je dan uiteindelijk 100% nauwkeurigheid bereiken, zolang je van zoveel/teveel variabelen afhankelijk ben. Vogelaars herkennen de vogels ook op het vergelijken van plaatjes, maar daarnaast houden ze ook een set kenmerken aan, die ze checken en kijken of die aanwezig zijn. Kan die set aan kenmerken ook niet ingebouwd worden in deze AI apps? Dat na het vergelijken van de plaatjes ook gekeken wordt of een dataset van x kenmerken ook op de vogel gevonden kan worden. Daaraan zou je dan ook nog een nauwkeurigheid kunnen hangen, bijvoorbeeld met het vinden van 4 van de 5 kenmerken scoor je 80%. En als je bovenstaande inbouwt, dan kan je dat, de kenmerken waarop de determinatie gebaseerd is, ook toevoegen aan de gegeven determinatie. Dan geef je niet alleen de juiste/verkeerde (vogel)naam, maar kan je ook een set aan kenmerken meegeven waarop de determinatie gebaseerd is. Dat kan men dan achteraf nog checken of het klopt en is ook nog leerzaam. Zeker dat laatste, leerzaam, ontbreekt bij de huidige apps, reden dat ik ze nu ook alleen aanraad als opstap voor een determinatie, nooit als eindelijke uitkomst.
Gewoon wat ideeën 😊

Peter de Knijff
·
31 oktober 2023 11:23
@Wietze, volgens mijn eigen ervaringen met AI herkenning is het juist een volslagen raadsel hoe het algoritme uiteindelijk besluit dat iets A is en niet B. Dus “onze” kenmerken kunnen heel erg goed genegeerd worden door deze software. Ik heb al bijna 10 jaar geleden (welliswaar met andere software en voor andere - forensische identificatie- doeleinden) samen met een paar buitenlandse AI experts getracht dit helder te krijgen. AI gebruiken was geen probleem, maar de exacte herkennigscriteria eruit halen (wat voor gebruik in een rechtbank cruciaal is - ja rechter, de software zegt is niet acceptabel) bleek helaas onmogelijk.
Het zou heel fraai zijn als AI mij kan vertellen hoe exact in onze ogen sterk gelijkende taxa te herkennen zijn, maar ik vrees dat dat een brug te ver is.
Als ik heb mis heb, hoor ik het graag. Ik gebruik het overigens heel vaak als een eerste richting bij de herkenning van voor mij onbekende insecten, waarna in vrijwel alle gevallen ik alsnog zelf aan de slag ga en iets gerichter de tabellen er bij kan pakken.

Jacob Lotz
·
31 oktober 2023 11:31, gewijzigd 31 oktober 2023 11:37
Duidelijke uitleg! Is het model ergens gedocumenteerd? Wat voor licentie heeft het model / zouden we het kunnen inzien? Ik kan me zo voorstellen dat als postdocs hier onderzoek mee doen het een keer naar een open source project gaat.
@Peter en Wietze: Ik ben ook zeker geen AI expert, maar het lijkt me dat je een model wel kan leren om kenmerken uit te leggen. Het model zal er zelf (nog) helemaal niks van begrijpen maar zou op basis van een foto aan kunnen wijzen welke kenmerken op de soort passen met bijbehorende onzekerheid. Het model zou bijvoorbeeld uit twee lagen kunnen bestaan: eerst soort herkenning en dan kenmerk herkenning.

Jan van der Laan
·
31 oktober 2023 20:26, gewijzigd 31 oktober 2023 20:29
Lang geleden al weer studeerde ik af in de cognitieve psychologie met als afstudeerrichting kunstmatige intelligente (AI). Daar was de meest gebruikte definitie van AI om computers dingen te laten doen waar mensen op dat moment beter (en vaak nog steeds) in waren. We probeerden daar zoveel mogelijk kennis van experts te modelleren om daaruit expertsystemen te bouwen. Bv een programma dat interactief vragen stelde om bv een aankomende hartinfarct te herkennen, meningitis of rugafwijkingen aan de de hand van gegevens die verkregen werden door patient/client op een lopende band te laten lopen.
Bij het laatste onderzoek vertelde mijn professor vol trots dat ze in het systeem een hoop expertregels hadden gestopt, maar waarbij ze veel kennis hadden verkregen van één patiënt, de zg benchmark patiënt. Op een dag was er een demo met diverse fysiotherapeuten en orthopeden als publiek. De patiënt met de gekende rugafwijking liep op de lopende band en daaruit rolde de diagnose. Het was ineens een totaal andere! De bouwers van het systeem zochten de weg naar de uitgang, verborgen zich achter het podium of deden alsof ze er niet bij hoorden. Totdat een van de fysio's zei, "hmm, volgens mij heeft-ie gelijk!"
Waar we toen eigenlijk tegenaan liepen was de hardware. Parellel processing konden computers nog nauwelijks of deden er een eeuwigheid over. Tegenwoordig is de hardware er wel op toegerust en heeft AI vooral de laatste 10 jaar een enorme vlucht genomen. Eigenlijk heeft het nauwelijks nog met AI te maken en is het niets meer dan brute rekenkracht en het zo snel mogelijk op zoek gaan naar de meest passende overeenkomst.
Het menselijke brein doet ook iets soortgelijks, maar is ook in staat om snel te kunnen besluiten dat iets niet in het bestand zit en gaat dan over op een andere strategie, namelijk een zg top-down benadering via een soort beslisboom.
Wim Wiegant heeft er ooit een uitstekende lezing over gegeven (m.i. zijn beste ooit), waarbij hij als bron blijkbaar het zelfde studieboek had gebruikt (Human Information Processing van Lindsay Norman), maar ook met nieuwe ontwikkelingen kwam, bv de zg Jennifer Anniston neuron.
Tot slot defineerden Paul de Heer en Edward van IJzendoorn min of meer de strategie die de toenmalige CDNA gebruikte om vogelwaarnemingen te beoordelen: 1) passen de waargenomen kenmerken op soort A, 2) sluiten de waargenomen kenmerken andere soorten uit en 3) rechtvaardigen de waarnemingsomstandigheden punten 1 en 2?
Deze regels kun je ook toepassen op je eigen waarnemingen. Zelf denk ik dat machine learning systemen alleen gebruik maken van stap 1. Voor ObsIdentify zou je stap 3 kunnen inbouwen: foto's die een zekere mate van onscherpte vertonen niet beoordelen en dat afdoen met de melding dat de foto te weinig details laat zien om tot een determinatie te komen. Altijd nog beter dan het advies een andere hobby te gaan zoeken (hoewel ik me die reactie kan voorstellen!).
Vincent Kalkman
·
2 november 2023 09:39, gewijzigd 2 november 2023 09:45
Hierboven staan veel vragen en ideeen. Ik probeer ze hieronder allemaal te adresseren.
Jan Hein van Steenis: Bij planten is het probleem vaak dat waarnemers alleen de bloem fotograferen, wat dan een antwoord oplevert dat niet te controleren is.
VJK: Dit is ook een grote frustratie bij de plantenvalidatoren in Nederland (vooral bij composieten en schermbloemen). Dit is deels een kwestie van het opvoeden van waarnemers, deels kunnen we bij de beeldherkenning betere foto’s gaan afdwingen en deels (mijn persoonlijke mening) moeten we misschien af van het idee dat elke waarneming goed- of afgekeurd moet worden. Er zijn zoveel waarnemingen en zoveel zijn zo onbenullig dat het niet erg is als ze ‘open blijven staan’.
Jan Hein van Steenis: De meeste mensen komen niet verder dan bloemperkjes en tuinen, wat dan weer tot rare antwoorden van de AI leidt (bijna elke exotische waarneming die ik in Duitsland tegenkom is een tuinplant die er totaal niet op lijkt).
VJK: In Duitsland is Observation/beeldherkenning sterk in opkomst met veel onervaren waarnemers en (te) weinig validatoren. Het percentage mensen dat lukraak bloemen in de tuin gaat fotograferen is daar (denk ik) hoger. Maar ook in Nederland blijft het een bron van ergernis.
Wietze Janse: ‘Hoe ga je 100% nauwkeurigheid bereiken & kenmerken waarop de determinatie gebaseerd is, ook toevoegen aan de gegeven determinatie’.
VJK: We gaan geen 100% nauwkeurigheid bereiken maar het gaat nog komende jaren elk jaar weer wat beter worden. Bedenk dat beeldherkenning nu ongeveer 5 jaar oud is en nu al bij een mystery bird competitie op een DB-dag vermoedelijk niet op de laatste plaats zou eindigen. Beeldherkenning kijkt nu niet expliciet naar kenmerken. Om dat wel te doen moet het systeem geleerd worden wat bijvoorbeeld een duimvleugel is. Om die bij alle vogels te herkennen heb je iemand nodig die op 10.000 foto's de duimvleugel aangeeft (etc voor achterteennagel, culmen, etc) en vervolgens expliciet beslisregels aangeeft. Dit is een beetje hoe ouderwetse beeldherkenning werkt. Het kan dus wel maar het is heel veel werk en voorlopig valt er meer winst te halen met allerlei andere zaken. Een van de dingen die we graag zouden willen (maar waar geen tijd voor is) is het betrekken van de waarnemer. Stel je maakt een foto van een schermbloem en je krijgt als reactie: ‘Deze plant behoort bij de schermbloemfamilie. 'Is de stengel hol of gevuld?’ of ‘Deze plant behoort bij de schermbloemfamilie, maak een foto van het blad voor verdere determinatie’.
Peter de Knijff: ‘Dus “onze” kenmerken kunnen heel erg goed genegeerd worden door deze software.’.
VJK: Dat is inderdaad waarschijnlijk vaak waar. Overigens herkennen wij de meeste dingen ook niet aan expliciete kenmerken. Als je een vork op tafel ziet liggen denk je ook niet: ‘he, een metaal glimmend voorwerp met aan de ene kant vier stevige scherpe punten’.
Jacob Lotz: het model ergens gedocumenteerd?
VJK: We hebben natuurlijk wel interne documentatie maar nog geen fraai artikel waar alles in beschreven staat. Dat komt deels omdat de focus ligt op het door ontwikkelen van het model en het schrijven van een artikel veel tijd kost terwijl de inhoud daarvan al achterhaald is voordat het uitkomt. De test dataset en modellen waar de Postdoc mee werkt worden wel gepubliceerd bij de artikelen. In hoeverre het model geheel open source wordt is nog onderwerp van discussie waarbij een balans nodig is tussen het zoveel mogelijk beschikbaar maken van kennis over biodiversiteit en het levensvatbaar houden van de verdere ontwikkeling. Persoonlijk speelt bij mij daar nog de ergernis mee over concurrerende biodiversiteitsportals waardoor validatoren op meerdere portals waarnemingen moeten controleren. Zo zou ik niet graag zien dat er in het buitenland allerlei ondoordachte portals worden opgezet die beeldherkenning aanbieden zonder dat er een sociale structuur van waarnemers en experts achter zit.
Jan van der Laan: 'Foto's die een zekere mate van onscherpte vertonen niet beoordelen en dat afdoen met de melding dat de foto te weinig details laat zien om tot een determinatie te komen.’
VJK: Er wordt gewerkt aan het weigeren van foto’s Het gaat daarbij om selfies, kamerplanten, collectie specimens en om wazige foto’s. Dit is niet allemaal gemakkelijk (je moet bijvoorbeeld zeker weten dat alle type mensen dezelfde kans hebben om geweigerd te worden). Opmerkelijk genoeg is het uitfilteren van onscherpe foto’s niet zo heel makkelijk. Foto’s zijn namelijk zelden helemaal onscherp en meestal gaat het om opnames waarbij de achtergrond haarscherp is met op de voorgrond een wazige vlek in de vorm van een vogel of plant.
Peter de Knijff
·
12 november 2023 17:36, gewijzigd 13 november 2023 16:17
Bedankt voor je reactie Vincent.
Een hilarisch voorbeeld van een NIA determinatie zag ik vandaag langskomen (ingevoerd als Rooddijschaduwwants - Apolygus limbatus).
Ik vind dat er een veel betere disclaimer moet komen zodat ook de onervaren gebruikers veel minder klakkeloos de determinatie accepteren. WRN.nl staat vol met dit soort gevallen, helaas een onbedoeld effect van het gebruiksgemak. In de berichtgeving over NIA wordt hier te weinig aandacht aan gegeven vind ik.

Ben Gaxiola
·
13 november 2023 21:30, gewijzigd 14 november 2023 08:29
@Peter,
Grappig is dan wel, dat ook de menselijke admin het fout heeft. :-)
Edit: ik vraag me af of dit wel een fout vd NIA is. De tekst van de admin suggereert dat het een invoerfout is in het Duits, waar deze beesten blijkbaar dezelfde naam hebben.
Peter de Knijff
·
14 november 2023 09:04, gewijzigd 14 november 2023 09:20
Ik ken de admin, dat is een wantsen specialist, en ja, ik vermoed nu ook dat het een taaldingetje is. Maar dan nog, klakkeloos suggesties aannemen is nu juist niet wat je moet doen. Overigens, ik heb de waarnemer een mailtje gestuurd met de juiste determinatie.
Naschrift, zelf een kopie van de foto ingevoerd, NIA geeft 99% Zwarte ruiter, wat dus best wel eens zou kunnen kloppen, en bevestigd dat dit inderdaad geen NIA dingetje is maar een taalissue.
Gebruikers van het forum gaan akkoord met de forumregels.